Contexto
Durante los últimos años he dedicado una cantidad desproporcionada de mi tiempo a ayudar a instituciones financieras a poner en producción sistemas de IA Generativa que realmente tienen que funcionar. No chatbots. No prototipos de fin de semana. Sistemas que extraen los documentos correctos para redactar un memorando de crédito, identifican la regulación adecuada para un oficial de LRR o de riesgo revisando una transacción transfronteriza, o filtran decenas de miles de documentos internos para que un equipo de búsqueda ejecutiva encuentre los tres que verdaderamente importan.
Lo que he notado es que, a pesar del constante tambor de "las ventanas de contexto se hacen más grandes, RAG está muerto", los casos de uso empresariales siguen apoyándose fuertemente en Retrieval Augmented Generation. Las razones no son glamorosas. Los documentos viven en distintos repositorios con distintos controles de acceso. Los reguladores quieren ver exactamente qué párrafo respaldó qué decisión. Las bases de conocimiento crecen más rápido de lo que cualquier ventana de contexto puede absorber. Incluso con un modelo de un millón de tokens, todavía hay que decidir cuál millón de tokens cargar, y esa decisión es precisamente el punto de RAG.
El problema real en este espacio no es que RAG haya dejado de ser útil. El problema es que, como casi todo en Inteligencia Artificial, el nombre sigue cambiando mientras la arquitectura subyacente se transforma drásticamente cada seis a doce meses. La frase "Agentic RAG" en 2024 significaba algo muy distinto a lo que significa en 2026, y la mayoría de las empresas que están comprando soluciones hoy no son conscientes de esa brecha.
Este artículo es un intento de mapear esa evolución con claridad, para que la próxima vez que alguien entre a tu oficina con una presentación titulada "Solución Agentic RAG", puedas hacer las preguntas correctas antes de firmar el SOW.
Una Breve Historia: Cómo Llegamos Hasta Aquí
El RAG Original (2023)
RAG se desarrolló durante la era de GPT-3.5-Turbo, cuando las ventanas de contexto rondaban entre 3,000 y 6,000 tokens. Toda la arquitectura era una solución para una restricción concreta: no podías meter una base de conocimiento en el prompt, así que tenías que recuperar los fragmentos más relevantes e inyectarlos en tiempo de ejecución. Las estrategias de chunking, el ajuste de embeddings y los pipelines de re-ranking eran consecuencias directas de esa limitación.
Vale la pena pausar aquí. Muchas de las técnicas que la gente sigue replicando por inercia en sistemas RAG modernos (p. ej., chunking agresivo, ventanas deslizantes, top-k fijo) existen por restricciones que ya no aplican. Las ventanas de contexto ahora están en los millones. Algunas de esas técnicas han envejecido convirtiéndose en buenas prácticas. Otras han envejecido convirtiéndose en trabajo innecesario.
Las Variantes de RAG
Después de que el RAG clásico demostrara su valor en los primeros despliegues empresariales, la comunidad produjo un flujo constante de variantes. Self-Improving RAG. GraphRAG. Hybrid RAG. Hierarchical RAG. AgenticRAG. Cada una resolvió un problema real (p. ej., baja recuperación en preguntas de múltiples saltos, desempeño débil sobre datos relacionales, incapacidad para refinar sus propias consultas) y cada una llegó con una ola de proveedores comercializándola como el nuevo estándar.
En el resto de este artículo quiero enfocarme específicamente en Agentic RAG, porque es la variante que más se ha movido y la que las empresas están comprando con mayor entusiasmo hoy, frecuentemente sin darse cuenta de que pueden estar comprando una arquitectura de 2025 envuelta en empaque de 2026.
Agentic RAG en 2024 / 2025
La primera ola de Agentic RAG apareció casi inmediatamente después de que los LLMs desarrollaran capacidad real de razonamiento. Una vez que los modelos pudieron razonar sobre sus entradas en lugar de simplemente predecir el siguiente token, dos cosas se volvieron posibles que antes no lo eran:
- El paso de recuperación podía evaluarse. El agente podía mirar los documentos que devolvía el vector store, decidir si realmente respondían la pregunta, y descartar los fragmentos que eran ruido. El RAG plano no tenía ese filtro. Lo que el modelo de embeddings devolviera, el LLM lo consumía.
- El paso de recuperación podía iterarse. En lugar de ejecutar una sola búsqueda por similitud y esperar lo mejor, el agente podía reformular la consulta, hacer una búsqueda de seguimiento, explorar regiones adyacentes del vector store y ensamblar los resultados en un contexto más rico. Esto fue particularmente poderoso para preguntas de múltiples saltos donde la respuesta no estaba en ningún fragmento individual.
Esta es también la arquitectura que la mayoría de los diagramas de "Agentic RAG" de 2024 y 2025 ilustran. Se ve más o menos así:
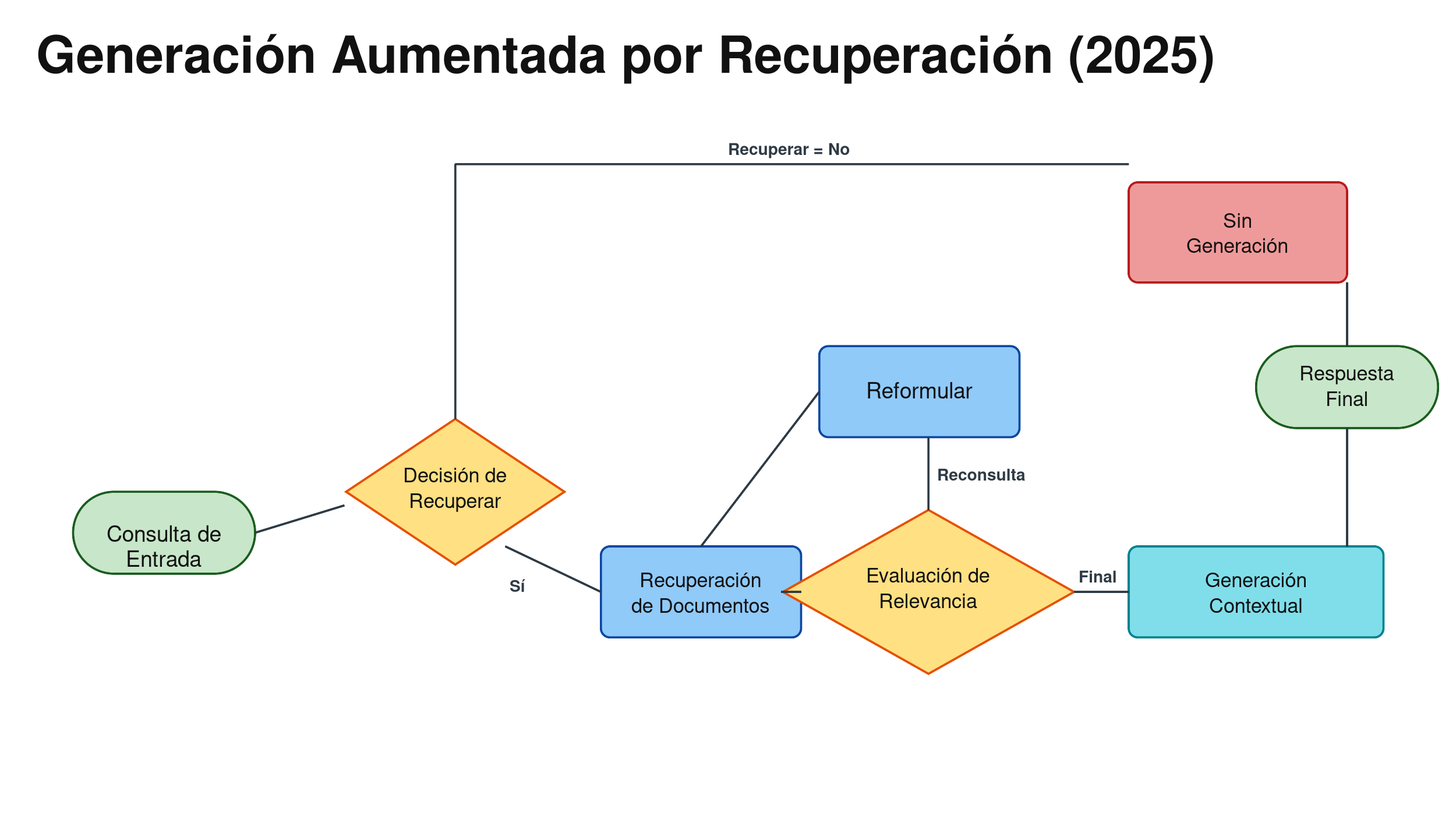
El flujo es intuitivo: la consulta de entrada llega a un nodo de Decisión de Recuperar que decide si la recuperación es siquiera necesaria. Si sí, los documentos se extraen del vector store, un nodo de Evaluación de Relevancia los califica, y o bien hace una reconsulta (vía un paso de Reformular) o procede a Generación Contextual. Si no se necesita recuperar, el agente salta directamente a la rama de Sin Generación / respuesta directa y produce una Respuesta Final.
Esto fue una mejora sustancial sobre el RAG plano. La recuperación se volvió condicional en lugar de refleja. Los fragmentos malos se filtraban. Las preguntas de múltiples saltos efectivamente se respondían. Por un tiempo fue razonable llamar a esto "agéntico" porque el agente, como mínimo, estaba tomando decisiones sobre su propio pipeline de recuperación.
Pero la arquitectura tenía dos límites estructurales que se hicieron más obvios cuando las empresas intentaron escalarla:
- Solo sabía hablar con un vector store. Los datos estructurados (p. ej., warehouses SQL, tablas transaccionales, blotters de posiciones) quedaban fuera de su mundo.
- No tenía manera de alcanzar el conocimiento al nivel de aplicación. Si la respuesta vivía dentro de un CRM, un sistema de tickets o una plataforma de filings regulatorios, el agente no tenía camino hacia ella sin que primero alguien hiciera ETL de esos datos al vector store.
Agentic RAG en 2026
La versión 2026 de Agentic RAG luce diferente no porque el marketing haya cambiado, sino porque tres cosas concretas cambiaron en el ecosistema subyacente:
- Por fin nos pusimos de acuerdo sobre qué es un "Agente". Un agente ahora se define consistentemente como un sistema que puede razonar sobre la tarea en cuestión, elegir la herramienta adecuada de un conjunto de herramientas disponibles, evaluar el contenido que la herramienta devuelve, y o bien generar una respuesta final o iterar de nuevo. El Agentic Loop (es decir, razonar → llamar herramienta → verificar → responder) ya es estándar, no una idea de investigación.
- Las ventanas de contexto cruzaron el umbral del millón de tokens. Esto no mató a RAG, pero sí cambió la economía. Ya no necesitas hacer chunking agresivo para que el contenido quepa. Puedes pasar documentos de política completos, releases de earnings completos o sets de contratos completos directamente al contexto. El trabajo de RAG ha cambiado de "comprimir para el contexto" a "seleccionar por relevancia".
- Los servidores MCP (Model Context Protocol) se volvieron la interfaz estándar para conocimiento de aplicación. Esta es la parte que la mayoría se pierde. MCP le da a las aplicaciones una manera de exponer endpoints de conocimiento dirigidos sin entregar su base de datos completa. Un sistema de core banking puede exponer un endpoint de "consultar posición del cliente". Una plataforma regulatoria puede exponer un endpoint de "obtener el último fallo de LRR". El agente le habla al servidor MCP, el servidor MCP le habla a la aplicación, y los datos de la empresa nunca dejan su frontera.
Cuando juntas esos tres cambios, la arquitectura deja de verse como un vector-store-con-bucle-de-feedback y empieza a verse así:
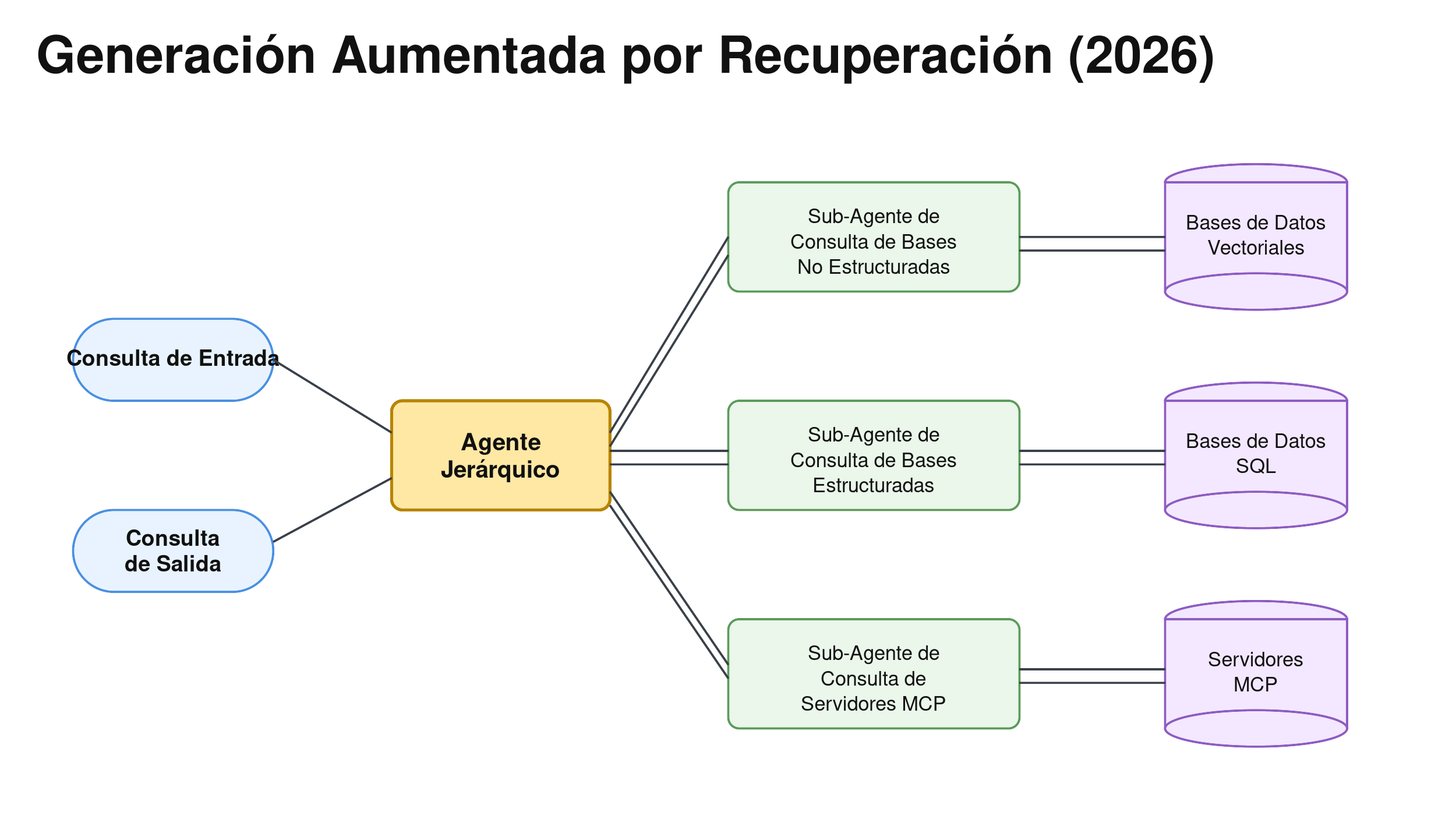
El Agentic RAG de 2026 tiene un Agente Jerárquico en el centro que razona sobre dónde es más probable que viva la respuesta y delega al sub-agente apropiado. Un Sub-Agente de Consulta de Bases No Estructuradas maneja la recuperación del vector store (esta es la pieza clásica de RAG). Un Sub-Agente de Consulta de Bases Estructuradas genera SQL o queries equivalentes contra datos transaccionales y de referencia. Un Sub-Agente de Consulta de Servidores MCP habla con aplicaciones empresariales a través de sus endpoints MCP. El agente jerárquico cose los resultados y produce una Consulta de Salida coherente.
Este es un sistema fundamentalmente distinto al de 2025. La arquitectura de 2025 era un pipeline de recuperación más inteligente. La arquitectura de 2026 es un orquestador federado de conocimiento que utiliza la recuperación como una de sus herramientas. El vector store ya no es el universo; es un solo componente dentro de un kit de herramientas más amplio.
Por Qué Importa Esta Distinción
Podrías estar tentado a leer lo anterior y concluir que esto es solo pedantería arquitectónica. No lo es. La distinción tiene consecuencias muy prácticas:
- Procurement. Cuando un proveedor te ofrece "Agentic RAG" en 2026, el diagrama de la slide tres debería verse como la arquitectura de 2026, no como la de 2025. Si todavía están dibujando un único bucle de vector store, estás comprando la solución del año pasado al precio de este año.
- Cobertura de casos de uso. Un Agentic RAG estilo 2025 no puede responder una pregunta como "¿cuál es la posición actual del cliente, qué dice nuestra última política de crédito sobre esa exposición y qué cambió el último filing regulatorio sobre los requisitos de reporte?". Esa única pregunta cruza datos estructurados, documentos no estructurados de política y un endpoint de conocimiento al nivel de aplicación. Solo la arquitectura de 2026 lo maneja de forma nativa.
- Residencia de datos y control de acceso. La capa MCP es la pieza que finalmente hace viable la búsqueda federada empresarial sin forzar a cada equipo a vaciar sus datos en un vector store central. Si tu proveedor de "Agentic RAG" no tiene una respuesta para MCP, no tiene una respuesta para el problema de conocimiento federado.
Qué Nos Enseña Esto
Algunas cosas, creo, vale la pena llevarse de ver evolucionar este término en tres años cortos.
La primera es que la mayoría de los conceptos en este campo están en evolución constante, y la capa de marketing rara vez sigue el ritmo. Firmar un contrato por "Agentic RAG" en 2026 sin especificar la arquitectura es el equivalente a firmar un contrato por "una base de datos" en 1999 sin especificar si querías un sistema relacional, un cubo OLAP o un key-value store. La etiqueta no está haciendo casi ningún trabajo.
La segunda es que los Arquitectos Agénticos necesitan mantenerse al día con la última terminología y con las arquitecturas detrás de ella para entregar soluciones de primera clase. Esto no es opcional. La vida media de un patrón arquitectónico en este espacio se mide en meses, no en años, y la brecha entre lo que era estado del arte hace doce meses y lo que es estado del arte hoy es lo suficientemente amplia como para que los clientes noten la diferencia en producción.
La tercera, y probablemente la más importante, es que las empresas deben estar listas y ser ágiles para cambiar arquitecturas a medida que las primitivas subyacentes cambian. Las instituciones que congelaron su arquitectura de RAG en 2024 ya están reconstruyendo. Las que congelaron su arquitectura de Agentic RAG en 2025 estarán reconstruyendo el próximo año. La única posición sostenible es asumir que la arquitectura va a evolucionar y construir tus sistemas con suficiente modularidad como para poder intercambiar componentes sin re-plataformar.
Si no lo haces, tus usuarios lo harán. Empezarán silenciosamente a usar herramientas más nuevas, frecuentemente fuera del radar de IT, que están haciendo mejor uso de la generación actual de arquitecturas de RAG y de agentes. Para cuando el equipo de procurement se entere, la migración ya ocurrió en la sombra.
Pensamiento Final
RAG no está muerto. RAG tampoco es lo que era en 2023, ni en 2024, ni en 2025. La disciplina consiste en seguir preguntando, cada seis meses: "¿qué significa este término ahora, y el sistema que estoy operando sigue siendo consistente con ese significado?". Los equipos que se hagan esa pregunta de manera regular seguirán construyendo sistemas que se sienten actuales. Los que no, seguirán pagando precios empresariales por la arquitectura del año pasado y preguntándose por qué sus usuarios siguen quejándose.
Si te llevas una sola cosa de este artículo, que sea esta: cuando alguien diga "Agentic RAG", pídele que dibuje el diagrama. El diagrama te dice qué año estás comprando en realidad.
Publicado originalmente en Substack
Leer en Substack →