Context
Over the last few years I have spent a disproportionate amount of my time helping financial institutions stand up Generative AI systems that actually have to work in production. Not chatbots. Not weekend prototypes. Systems that pull the right documents to draft a credit memo, surface the right regulation for an LRR or risk officer reviewing a cross-border transaction, or sift through tens of thousands of internal documents so an executive search team can find the three that actually matter.
What I have noticed is that despite the constant drumbeat of "context windows are getting bigger, RAG is dead," enterprise use cases continue to lean heavily on Retrieval Augmented Generation. The reasons are not glamorous. Documents live in different repositories with different access controls. Regulators want to see exactly which paragraph supported which decision. Knowledge bases grow faster than any context window can keep up with. Even with a million-token model, you still have to decide which million tokens to load, and that decision is the entire point of RAG.
The real problem in this space is not that RAG has stopped being useful. The problem is that, like most things in Artificial Intelligence, the name keeps changing while the architecture underneath shifts dramatically every six to twelve months. The phrase "Agentic RAG" in 2024 meant something very different than it does in 2026, and most enterprises buying solutions today are not aware of the gap.
This article is an attempt to map that evolution clearly, so that the next time someone walks into your office with a slide deck titled "Agentic RAG Solution," you can ask the right questions before signing the SOW.
A Quick History: How We Got Here
The Original RAG (2023)
RAG was developed back in the GPT-3.5-Turbo era when context windows were sitting in the 3,000 to 6,000 token range. The whole architecture was a workaround for a hard constraint: you could not fit a knowledge base into the prompt, so you had to retrieve the most relevant fragments and inject them at runtime. Chunking strategies, embedding tuning, and re-ranking pipelines were all downstream consequences of that limitation.
It is worth pausing here. Many of the techniques people still cargo-cult into modern RAG systems (e.g., aggressive chunking, sliding windows, fixed top-k retrieval) exist because of constraints that no longer apply. Context windows are now in the millions. Some of those techniques have aged into best practices. Others have aged into busywork.
The RAG Variants
After classic RAG proved itself in early enterprise deployments, the community produced a steady stream of variants. Self-Improving RAG. GraphRAG. Hybrid RAG. Hierarchical RAG. AgenticRAG. Each one solved a real problem (e.g., poor recall on multi-hop questions, weak performance on relational data, inability to refine its own queries) and each one came with a wave of vendors marketing it as the new standard.
For the rest of this article I want to focus on Agentic RAG specifically, because it is the variant that has moved the most and the variant that enterprises are most actively buying today, often without realizing they may be buying a 2025 architecture in a 2026 wrapper.
Agentic RAG in 2024 / 2025
The first wave of Agentic RAG showed up almost immediately after LLMs developed real reasoning capability. Once the models could reason about their inputs rather than simply predicting the next token, two things became possible that were not possible before:
- The retrieval step could be evaluated. The agent could look at the documents the vector store returned, decide whether they actually answered the question, and discard the chunks that were noise. Plain vanilla RAG had no such filter. Whatever the embedding model surfaced, the LLM consumed.
- The retrieval step could be iterated. Instead of running a single similarity search and hoping for the best, the agent could rephrase the query, run a follow-up search, explore adjacent regions of the vector store, and stitch the results into a richer context. This was particularly powerful for multi-hop questions where the answer was not in any single chunk.
This is also the architecture that most "Agentic RAG" diagrams from 2024 and 2025 are illustrating. It looks something like this:
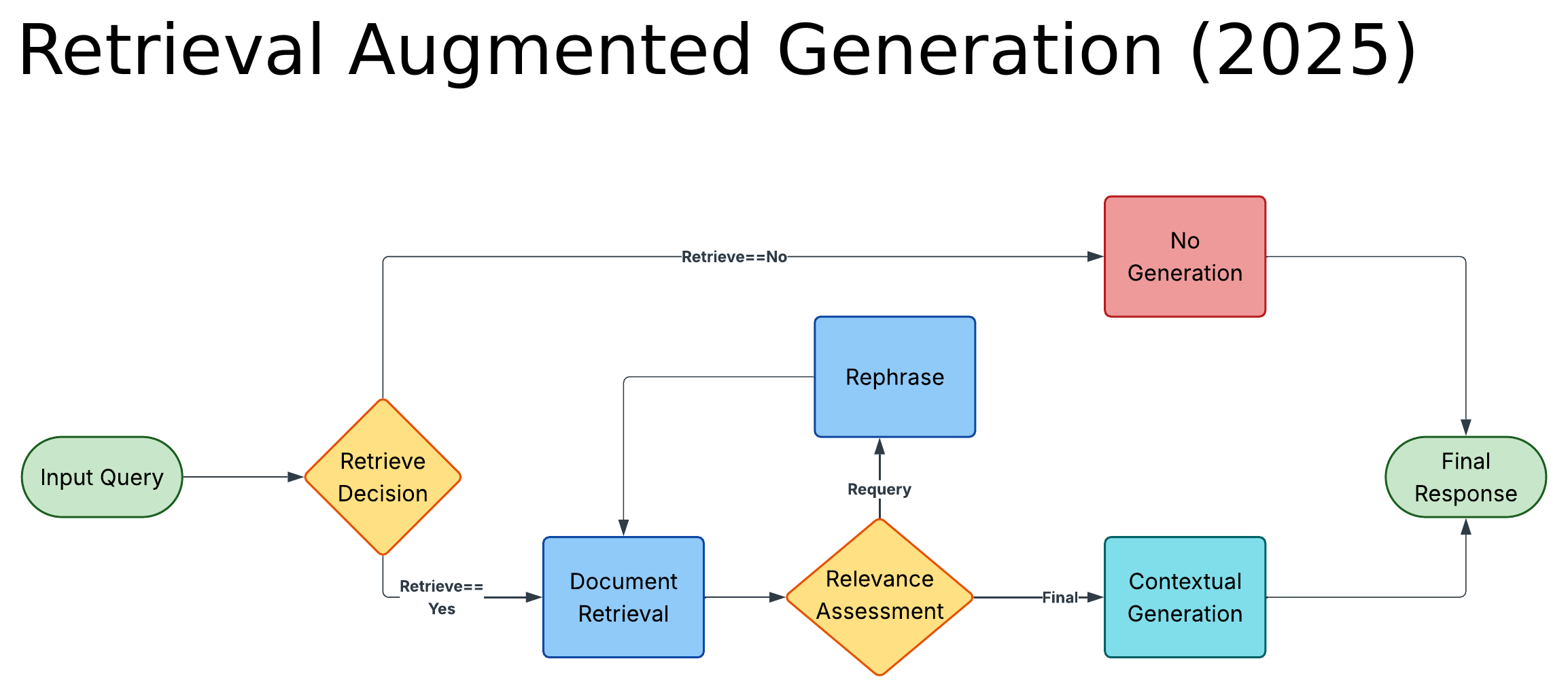
The flow is intuitive: the input query hits a Retrieve Decision node which decides whether retrieval is even necessary. If yes, documents are pulled from the vector store, a Relevance Assessment node grades them, and either re-queries (via a Rephrase step) or proceeds to Contextual Generation. If no retrieval is needed, the agent skips straight to a No Generation / direct response branch and produces a Final Response.
This was a substantial improvement over plain vanilla RAG. Retrieval became conditional rather than reflexive. Bad chunks got filtered. Multi-hop questions actually got answered. For a while it was reasonable to call this "agentic" because the agent was, at minimum, making decisions about its own retrieval pipeline.
But the architecture had two structural limits that became more obvious as enterprises tried to scale it:
- It only knew how to talk to a vector store. Structured data (e.g., SQL warehouses, transaction tables, position blotters) was outside its world.
- It had no way to reach into application-level knowledge. If the answer lived inside a CRM, a ticketing system, or a regulatory filing platform, the agent had no path to it without someone first ETL'ing that data into the vector store.
Agentic RAG in 2026
The 2026 version of Agentic RAG looks different not because the marketing changed, but because three concrete things changed in the underlying ecosystem:
- We finally settled on what an "Agent" actually is. An agent is now consistently defined as a system that can reason about the task at hand, choose the appropriate tool from a set of available tools, evaluate the content the tool returns, and either generate a final response or loop again. The Agentic Loop (i.e., reason → tool call → check → respond) is now table stakes, not a research idea.
- Context windows crossed the one million token threshold. This did not kill RAG, but it did change the economics. You no longer need to chunk aggressively to fit content. You can pass entire policy documents, full earnings releases, or complete contract sets directly into context. RAG's job has shifted from "compress for context" to "select for relevance."
- MCP (Model Context Protocol) servers became the standard interface for application knowledge. This is the part most people miss. MCP gives applications a way to expose targeted knowledge endpoints without handing over their full database. A core banking system can expose a "look up customer position" endpoint. A regulatory platform can expose a "fetch latest LRR ruling" endpoint. The agent talks to the MCP server, the MCP server talks to the application, and the enterprise data never leaves its boundary.
When you put those three changes together, the architecture stops looking like a vector-store-with-feedback-loop and starts looking like this:
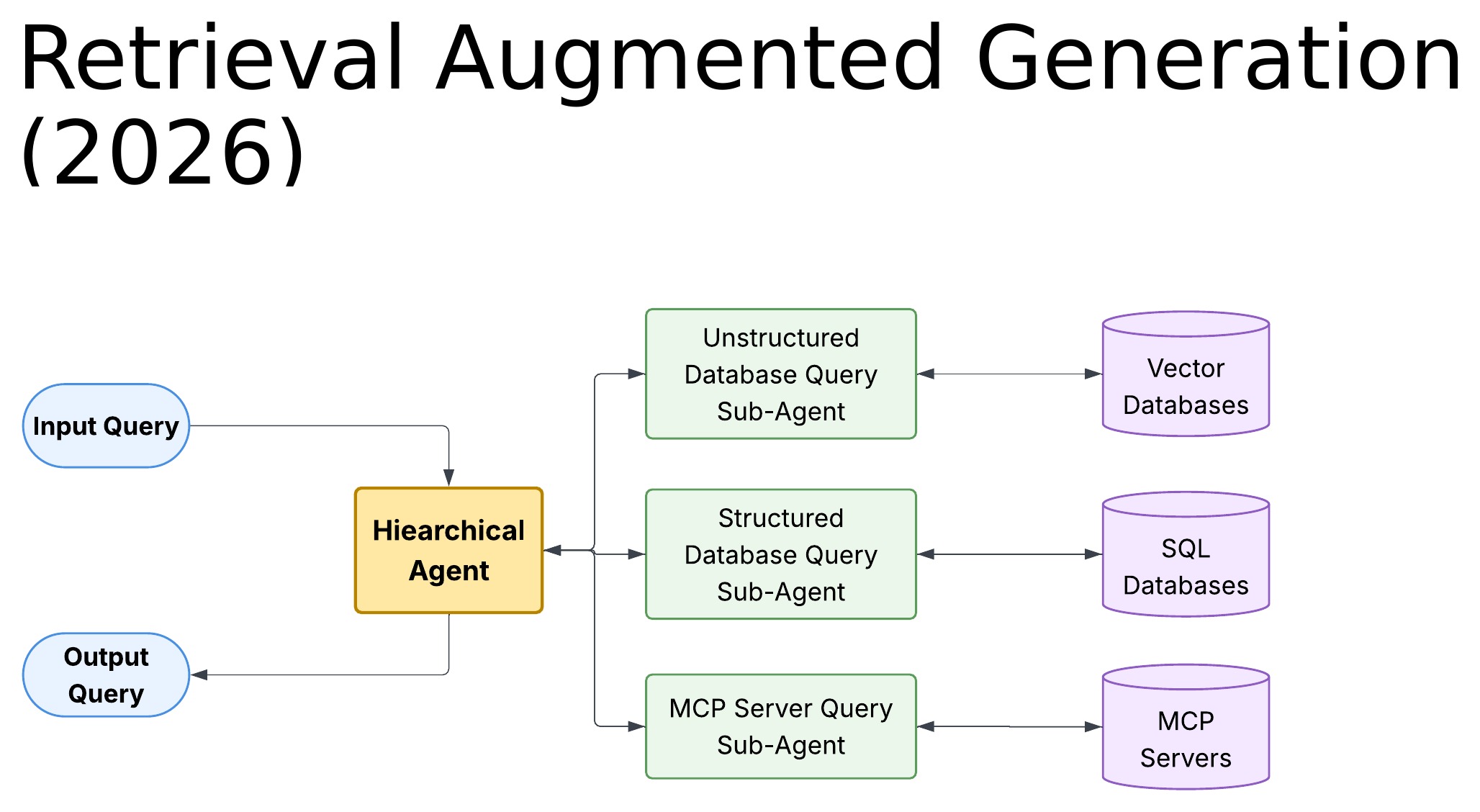
The 2026 Agentic RAG has a Hierarchical Agent at its center that reasons about where the answer is most likely to live and dispatches to the appropriate sub-agent. An Unstructured Database Query Sub-Agent handles vector store retrieval (this is the classical RAG piece). A Structured Database Query Sub-Agent generates SQL or equivalent queries against transactional and reference data. An MCP Server Query Sub-Agent talks to enterprise applications through their MCP endpoints. The hierarchical agent stitches the results together and produces a coherent Output Query.
This is a fundamentally different system than the 2025 version. The 2025 architecture was a smarter retrieval pipeline. The 2026 architecture is a federated knowledge orchestrator that happens to use retrieval as one of its tools. The vector store is no longer the universe; it is a single component in a wider toolkit.
Why This Distinction Matters
You might be tempted to read the above and conclude this is just architectural pedantry. It is not. The distinction has very practical consequences:
- Procurement. When a vendor pitches "Agentic RAG" in 2026, the diagram on slide three should look like the 2026 architecture, not the 2025 one. If they are still drawing a single vector-store loop, you are buying last year's solution at this year's price.
- Use case coverage. A 2025-style Agentic RAG cannot answer a question like "what is the customer's current position, what does our latest credit policy say about that exposure, and what did the latest regulatory filing change about reporting requirements?" That single question crosses structured data, unstructured policy documents, and an application-level knowledge endpoint. Only the 2026 architecture handles it natively.
- Data residency and access control. The MCP layer is the part that finally makes federated enterprise search viable without forcing every team to dump their data into a central vector store. If your "Agentic RAG" provider does not have an answer for MCP, they do not have an answer for the federated knowledge problem.
What This Teaches Us
A few things, I think, are worth taking away from watching this term evolve over three short years.
The first is that most concepts in this field are ever-evolving, and the marketing layer rarely keeps up. Signing a contract for "Agentic RAG" in 2026 without specifying the architecture is the equivalent of signing a contract for "a database" in 1999 without specifying whether you wanted a relational system, an OLAP cube, or a key-value store. The label is doing almost no work.
The second is that Agentic Architects need to keep up with the latest terminology and the architectures behind it to deliver best-in-class solutions. This is not optional. The half-life of an architectural pattern in this space is measured in months, not years, and the gap between what was state-of-the-art twelve months ago and what is state-of-the-art today is wide enough that customers will notice the difference in production.
The third, and probably the most important, is that enterprises must be ready and nimble enough to change architectures as the underlying primitives change. The institutions that froze their RAG architecture in 2024 are now rebuilding. The ones that froze their Agentic RAG architecture in 2025 will be rebuilding next year. The only sustainable position is to assume the architecture will evolve and to build your systems modularly enough that you can swap components without re-platforming.
If you do not, your users will. They will quietly start using newer tools, often outside of IT's purview, that are making better use of the current generation of RAG and agent architectures. By the time the procurement team notices, the migration has already happened in shadow.
Closing Thought
RAG is not dead. RAG is also not what it was in 2023, or in 2024, or in 2025. The discipline is to keep asking, every six months, "what does this term mean now, and is the system I am running still consistent with that meaning?" The teams that ask that question regularly will keep building systems that feel current. The teams that do not will keep paying enterprise prices for last year's architecture and wondering why their users keep complaining.
If you take away one thing from this piece, let it be this: when someone says "Agentic RAG," ask them to draw the diagram. The diagram tells you what year you are actually buying.
Originally published on Substack
Read on Substack →